Graph-Theory
- Graph 자료구조를 기반으로 하는 알고리즘들이다.
- Graph는 Node와 이를 연결하는 Edge로 구성되어있으며, 네트워크 토폴로지, 관계데이터, 전산, 수학에서 사용된다.
1. Graph 탐색 알고리즘
- Graph 상의 모든 Node를 방문하여 탐색하는 알고리즘
- DFS와 BFS가 있다.
2. 최단경로 알고리즘
- 두 노드 사이의 최단 경로를 찾는 알고리즘. 가중치가 없는 graph에서는 BFS를 사용할 수 있으며, 가중치가 있는 graph에서는 다익스트라, 벨만-포드, 플로이드-워셜 알고리즘이 사용된다.
3. 최소신장트리 알고리즘
- graph에서 모든 노드를 연결하면서 가중치의 합이 최소가 되는 트리를 찾는 알고리즘.
- 크루스칼, 프림 등이 있다.
4. 네트워크 플로우 알고리즘
- 유향 가중치 그래프에서 두 노드 사이의 최대 플로우를 찾는 알고리즘
- 포드-풀커슨, 에드몬드스-카프 등이 있다.
5. 이분매칭 알고리즘
- 이분 graph에서 최대매칭을 찾는 알고리즘
- 최대매칭이란 ? : 서로 다른 그룹의 노드를 최대한 많이 연결하는 것.
- 홉크롭프트-카프 알고리즘
6. 위상정렬, SCC, LCA, Graph Coloring 등의 알고리즘들이 있다.
Graph 자료구조의 이해
- Node와 Edge로 이루어진 자료구조
- 연결된 객체 간의 관계를 표현하는 자료구조이다.
- 여러개의 고립된 부분 그래프(Isolated Subgraphs)로 구성될 수 있다.
1. 용어
- 정점(vertex) : 위치(Node)
- 간선(edge) : 관계(link, branch)
- 인접 정점(adjacent vertex) : 간선에 의해 직접 연결된 정점
- 정점의 차수(degree) : 무방향 그래프에서 하나의 정점에 인접한 정점의 수
무방향 그래프에서 존재하는 정점의 모든 차수의 합 = 그래프의 간선 수의 2배
- 진입차수(내차수) : 외부에서 오는 간선의 수
- 진출차수(외차수) : 외부로 향하는 간선의 수
- 경로길이 : 경로를 구성하는데에 사용된 간선의 수
- 단순경로 : 경로 중에서 반복되는 정점이 없는 경우
- cycle : 단순경로의 시작정점과 종료정점이 동일한 경우
2. Graph의 특징
- 네트워크 모델이다
- 2개 이상의 경로가 가능하다 (양방향)
- Self loop 뿐만 아니라 loop/circuit 모두 가능하다.
- 루트노드 개념이 없다.
- 부모-자식 개념이 없다.
- 순회는 DFS, BFS로 이루어진다.
- 순환 혹은 비순환이다.
- 방향 graph, 무방향 graph가 있다.
- graph에 따라 간선의 유무가 다르다.
3. Graph의 종류
- 무방향 : 간선은 간선을 통해 양방향으로 갈 수 있다.
A와 B를 연결하는 간선은 (A,B) 로 표현된다. (A,B) === (B,A)
- 방향 : 방향성이 존재한다.
A와 B를 연결하는 간선은 <A,B>로 표현된다. <A,B> !== <B,A>
- 가중치 (Weighted Graph) : 간선에 비용이나 가중치가 할당된 graph. (Network)
- 연결 : 무방향 graph에 있는 모든 정점쌍에 대해서 항상 경로가 존재하는 경우
- 비연결 : 특정 정점쌍 사이에 경로가 존재하지 않는 경우
- Cycle : 단순경로의 시작정점과 종료정점이 동일한 경우
- 비Cycle : 사이클이 없는 graph
- 완전 : graph에 속한 모든 정점이 서로 연결되어있는 graph.
무방향 완전그래프 : 정점수가 n이면 간선의 수는 n*(n-1)/2 이다.
4-1. Graph의 구현(JS) - 인접리스트
- 인접리스트(Adjacency List) : 가장 일반적인 방법이며, 모든 정점을 인접리스트에 저장한다.
- 각각의 정점에 인접한 정점들을 리스트로 표시한다.
Adjacency List
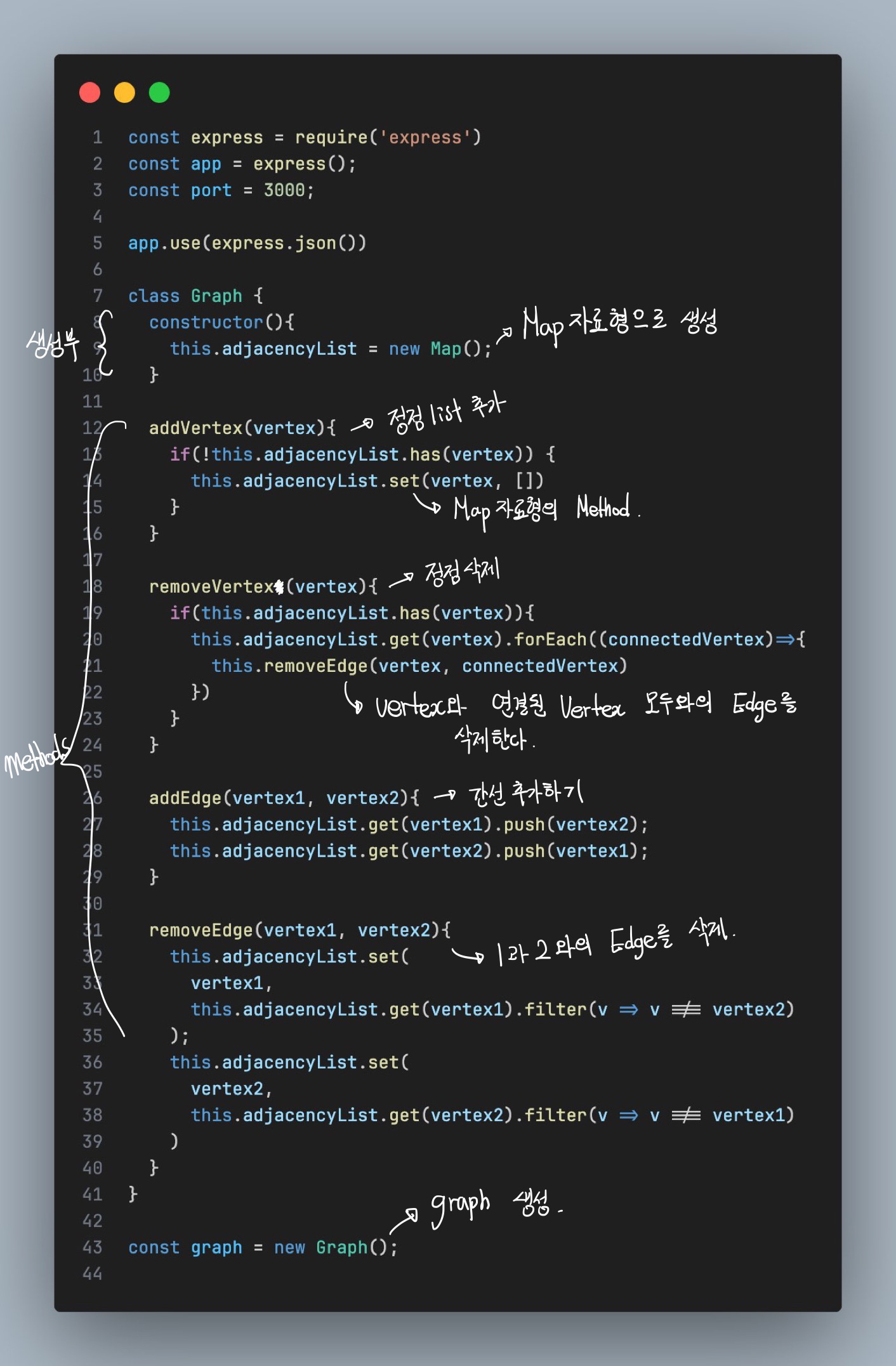
- 인접리스트 class의 인스턴스는 다음과 같이 표현된다.
{
A: [B, C],
B: [A, D],
C: [A, D],
D: [B, C]
}
4-2. Graph의 구현(JS) - 인접행렬
- 그래프의 노드들 사이의 연결을 행렬로 표현하는 방법.
- 행과 열은 각각 그래프의 노드를 나타내며, 행렬의 값은 두 노드 사이의 간선의 유무 또는 가중치를 나타낸다.
인접 행렬 표현(간선이 있는 경우 1, 없는경우 0)

인접행렬의 구현
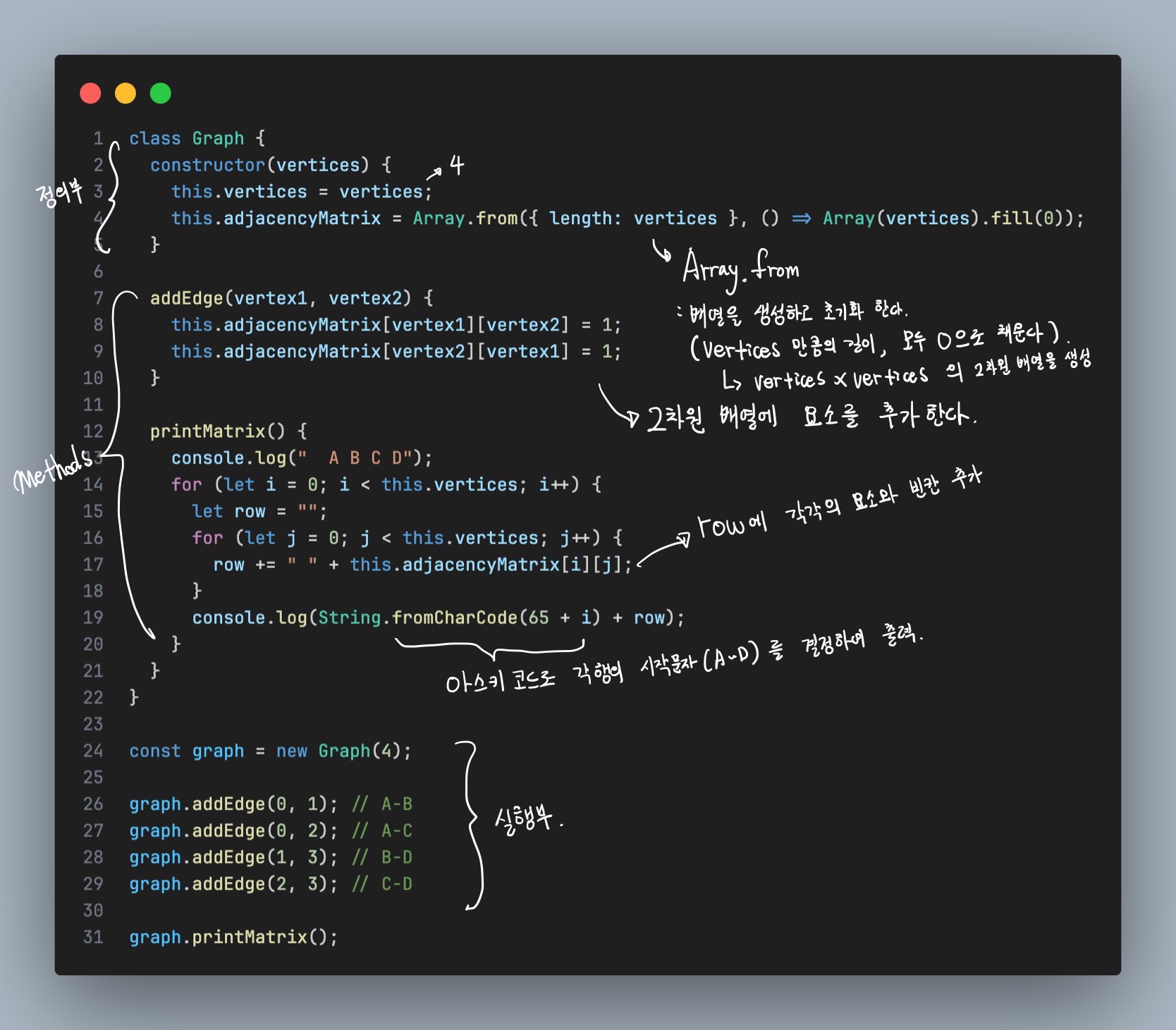
- 인접 리스트와 인접 행렬은 각각 그래프의 특성과 필요한 연산에 따라 장단점이 있다.
- 인접 리스트 : 메모리 사용량이 적고, 희소 그래프(sparse graph)에 적합하다. 그래프에 존재하는 모든 간선의 수 는 O(N+E) 안에 알 수 있다.
- 인접 행렬 : 두 노드 사이의 간선 유무를 빠르게 확인할 수 있다. 밀집 그래프(dense graph)에 적합하다. 정점의 차수 는 O(N) 안에 알 수 있다.
5. 그래프의 탐색
- 그래프 자료구조에서 탐색은 그래프의 노드들을 방문하는 과정이다.
- 주로 두가지 알고리즘이 사용된다.
- DFS(Depth-First Search) : 깊이 우선 탐색
- BFS(Breadth-First Search) : 너비 우선 탐색
DFS : 깊이우선탐색
- 개요 : 한 노드에서 시작하여 가능한 한 깊이 들어가면서 그래프를 탐색한다. 재귀 또는 스택을 사용해서 구현한다.
- 알고리즘 :
1) 시작 노드를 방문하고, 방문한 노드를 표시한다.
2) 시작 노드의 인접한 노드 중 아직 방문하지 않은 노드가 있다면, 그 노드를 시작 노드로 하여 DFS를 다시 실행한다.
3) 모든 인접한 노드를 방문했다면, 이전 노드로 돌아가서 다른 인접한 노드를 찾고 반복한다.
4) 모든 노드를 방문할 때 까지 이 과정을 계속한다.
BFS : 너비 우선 탐색
- 개요 : 한 노드에서 시작하여 해당 노드의 모든 이웃 노드를 방문한 후, 각 이웃 노드의 이웃들을 차례대로 방문하는 방식으로 그래프를 탐색한다. 큐를 사용하여 구현한다.
- 알고리즘 :
1) 시작 노드를 방문하고, 방문한 노드를 표시한다. 시작 노드를 큐에 넣는다.
2) 큐가 비어있지 않다면, 큐에서 노드를 꺼낸다.
3) 꺼낸 노드의 인접한 노드 중 아직 방문하지 않은 노드를 모두 방문하고, 방문한 노드를 표시하며 큐에 넣는다.
4) 큐가 빌 때까지 이 과정을 반복한다.
장단점과 특징
DFS : 미로찾기, 사이클검출, 연결성분찾기 등에 사용된다.
- 재귀 호출 사용 시 시스템 스택에 의존하므로, 스택 오버플로우가 발생할 수 있다. 해결을 위해 명시적으로 스택을 사용하여 반복적인 구현을 사용할 수 있다.
BFS : 최단경로문제, 두 노드 간의 최소 간선 수를 찾는 문제 등에 사용된다.
- 큐를 이용하므로, 큐의 크기가 커질 수 있다. 큰 그래프에서 메모리 사용량이 높아진다. 이 문제 해결을 위해 BFS의 변형인 양방향 탐색을 사용 할 수 있다. 양방향 탐색은 두 개의 동시 BFS를 시작 노드와 목표 노드에서 실행하고, 두 탐색이 만나는 지점에서 경로를 구성한다. (메모리 사용량을 줄이는데 도움이 된다.)
cf) 휴리스틱 함수를 사용하여 탐색 과정을 안내하는 A*알고리즘같은 최적화 탐색 알고리즘도 사용할 수 있다. 그래프에서 목표 노드까지의 예상 최소 비용을 고려하여 탐색을 수행하며, 효율적인 경로 찾기에 사용된다.
'ComputerScience > 알고리즘, 프로그래머스' 카테고리의 다른 글
| [Algorithm] Graph-Theory - 3 : DFS와 BFS 한방에 이해하기. (0) | 2023.04.03 |
|---|---|
| [Algorithm] Graph-Theory - 2 : JS로 구현과 시각화 (0) | 2023.03.31 |
| [Algorithm] 누적합 (0) | 2023.03.31 |
| [Lv.2] 튜플(카카오 인턴십 코딩테스트) (0) | 2023.02.20 |
| [Lv.2] 위장 (Hash와 경우의 수) (0) | 2023.02.20 |




댓글